유튜브와 넷플릭스를 보면 제가 본 영화나 드라마와 비슷한 느낌의 콘텐츠가 추천되는 걸 본 적이 있나요?
이는 바로 여러분이 아르고 리듬(Argorithm)의 선택을 받았다는 것! 이 알고리즘에 대해서는 많이 들어보셨을 겁니다.
사전적으로 해석하면 어떤 문제를 해결하기 위한 절차, 방법, 명령어 집합을 의미합니다.
다양한 플랫폼은 이 알고리즘을 통해 사용자들이 시청한 영상 기록을 수집하고, 어떤 장르를 좋아하는지 예측하고 맞춤형 콘텐츠를 보여주는 방법입니다.
이 과정에서 넷플릭스는 추천 알고리즘을 개선하기 위해 상금 10억이 걸린 대회를 개최하여 소비자를 2천 개 이상의 집단으로 세분화하는 등 매우 디테일한 타깃을 선정하였습니다.
유튜브는 이용자의 70%는 추천 알고리즘을 바탕으로 새로운 작품을 탐색하고 감상할 수 있도록 했으며 부적절하고 품질이 낮은 동영상 필터링을 위해 1년에 30회 이상의 알고리즘을 수정하는 과정을 거치고 있습니다.
여러 기업들이 이렇게 추천하고 리듬을 개선하고 발전시키려고 노력하는 이유는
소비자 이탈을 방지하고 고객 충성도(loyalty)를 높여 안정적인 수익 기반을 마련하는 데 중요한 역할을 하는 알고리즘으로 급부상했기 때문입니다.
이제 이런 알고리즘이 어떻게 만들어지는 빅재미를 통해 함께 분석해 볼까요?
분석의 전체적인 흐름
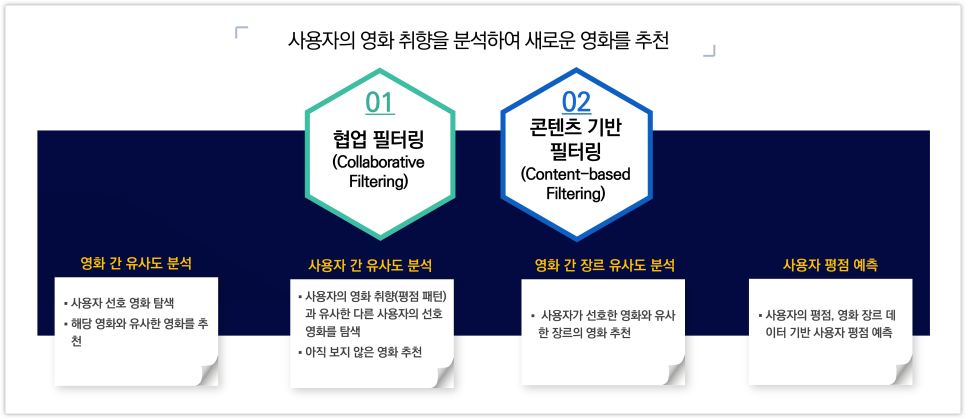
추천 시스템으로는 크게 협업 필터링(Collaborative Filtering) 콘텐츠 기반 필터링(Content-based Filtering) 두 가지가 대표적입니다.
전체적인 절차는 아래와 같이 진행될 예정입니다!
영화 간 유사도 분석 ↓ 사용자 간 유사도 분석 ↓ 영화 간 장르 유사도 분석 ↓ 사용자 평점 예측
수집 DATA(공공 데이터)
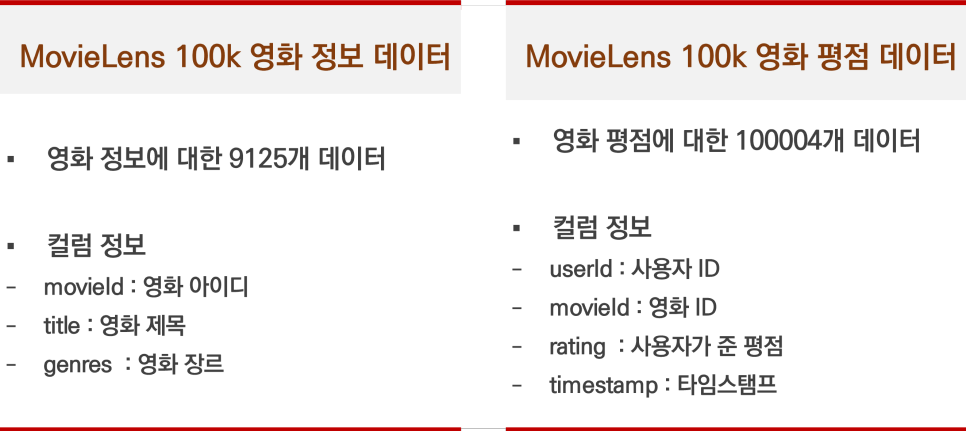
Movie Lens 100k 영화 정보 데이터 영화 정보에 관한 9,125개의 데이터를 수집하고, movie Id(영화 ID), title(영화 제목), genres(영화 장르)를 이용했습니다.
Movie Lens 100k 영화 평점 데이터 영화 평점에 대한 100,004개의 데이터를 수집하여 userId(사용자 ID), movieId(영화 ID), rating(사용자 평점), timestamp(타임스탬프)를 이용하였습니다.
영화정보 및 평가데이터 들여다보기
영화 평점 데이터의 탐색적 데이터 분석(EDA)을 통해
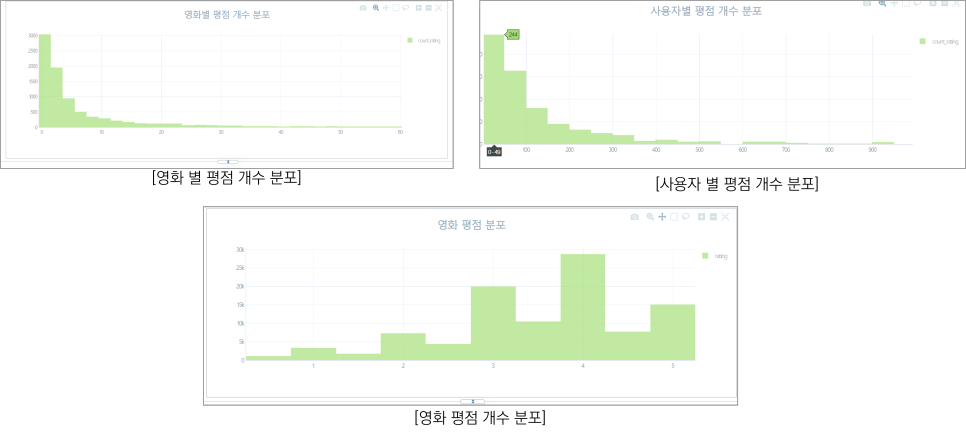
영화별 평점 개수 분포 시각화 사용자별 평점 개수 분포 시각화 평점 분포 시각화
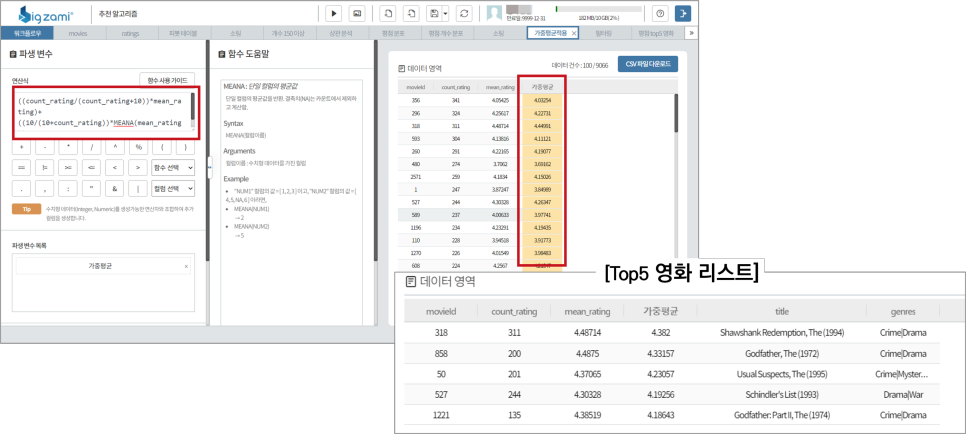
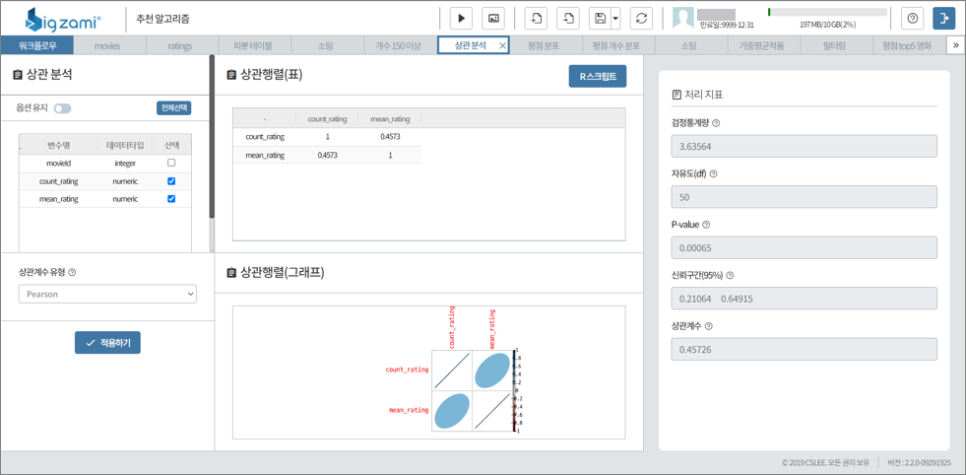
평점 개수와 평점 간 상관분석 가중평점을 산출하여 Top5 영화 목록을 완성
자, 이렇게 시각화 세 가지, 분석 두 가지 결과를 확인했어요.

시각화 그래프에서 영화별, 사용자별 평점 개수 분포를 확인하는 것 외에도 전체적인 영화 평점이 3~5점 사이에 가장 많은 분포를 보이는 것을 알 수 있겠죠?
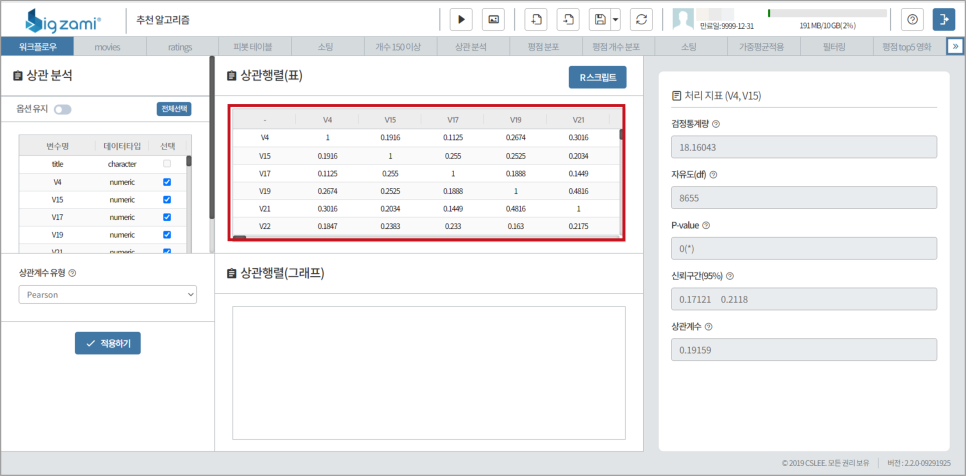
우리가해당데이터를이용해서상관분석을해보면평점개수가150개이상일때평점개수와평점평균간이약한양의상관관계가있음을알수있습니다.
의미있는 결과 도출을 위해 평점 개수에 가중치를 부여함으로써 가중평점을 산출했습니다
해당 분석에 사용된 연산식은 다음과 같으니 참고해주세요!
(Weighted Rating)=(v/(m+v))*R+(m/(v+m))*Cv:개별 영화에 평점을 투표한 횟수 m:평점을 주기 위한 최소 투표 횟수 R:개별 영화에 대한 평균 평점 C:전체 영화에 대한 평균 평점
사용자기반협업필터링

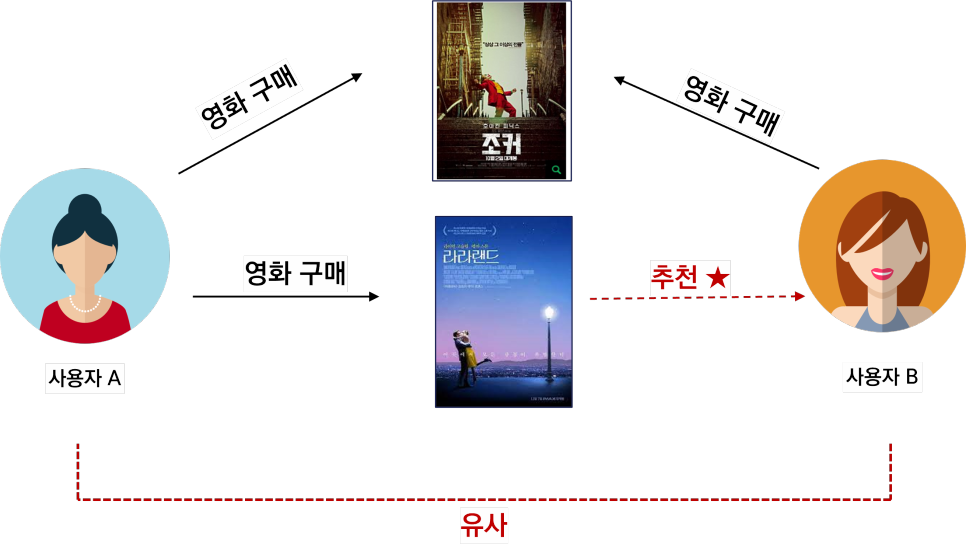
자신과 타인의 취향을 분석해서 취향이 비슷했던 사용자가 좋아했던 영화를 자신에게도 추천하는 방식입니다

사용자가 영화 ‘조커’를 보면 조커를 본 사람이 좋아하는 영화 ‘라라랜드’를 추천해줘요.
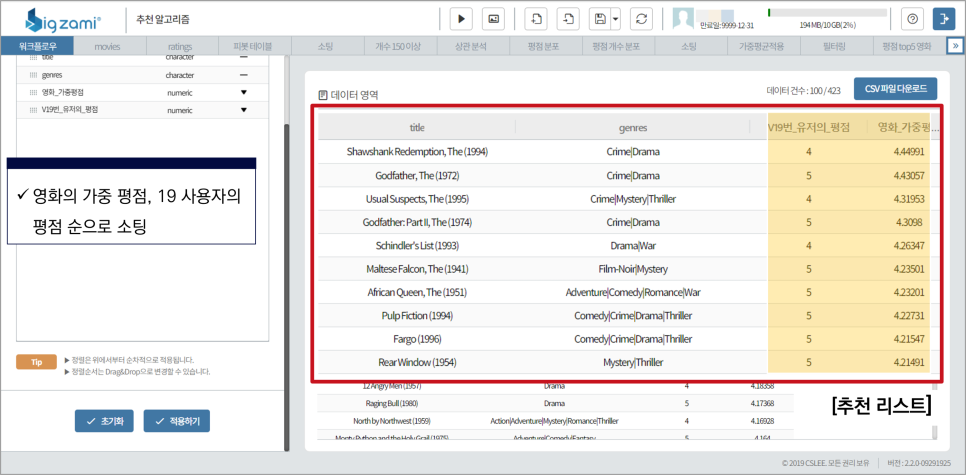
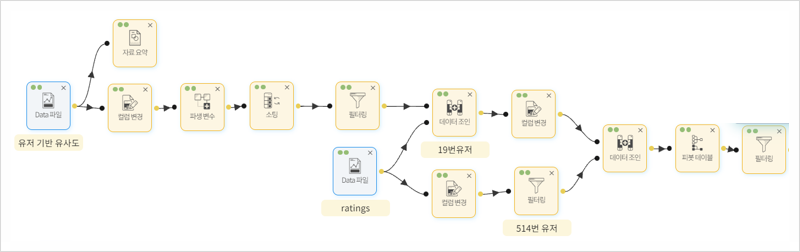
사용자 기반의 협업 필터링 전체 시나리오 순서, 지금부터 영화 데이터와 평점 데이터를 이용해 분석해 줍니다!
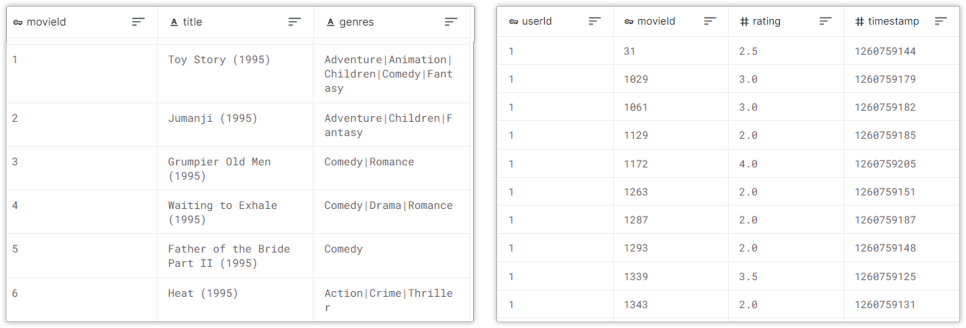
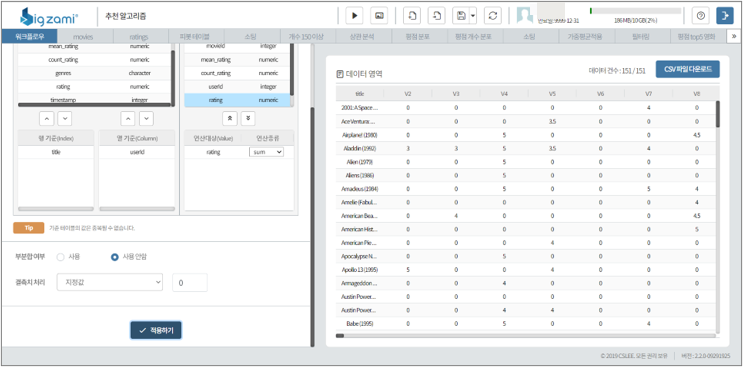
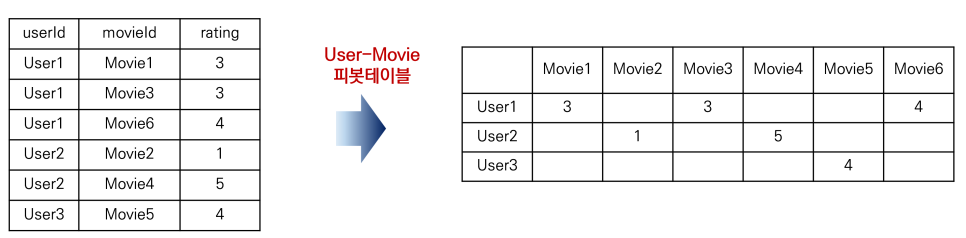
먼저 userid와 title로 피벗 테이블을 만들고 사용자가 평가한 평점을 바탕으로 유사도 행렬을 구한 후
사용자간의 유사도 측정을 위해 상관 분석으로 피어슨 유사도를 분석합니다.

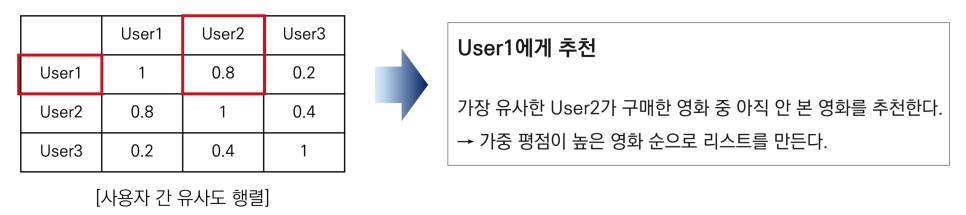
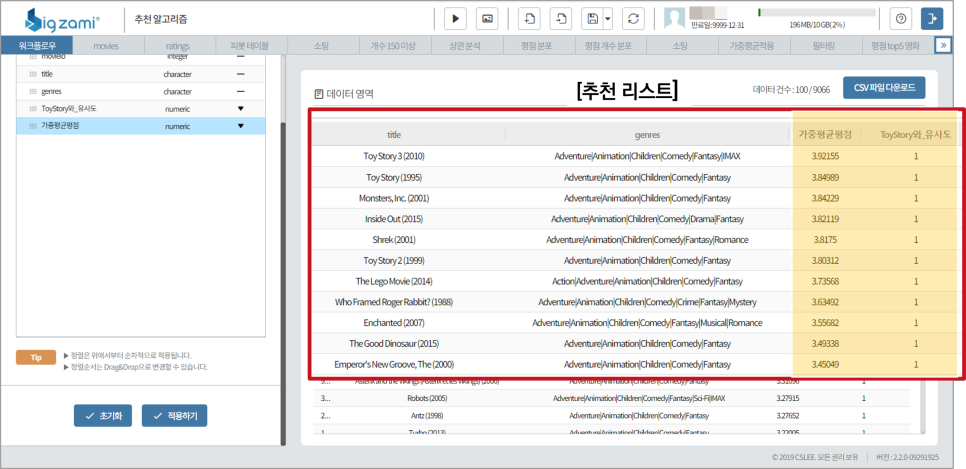
기본적인 원리는 위 표와 같이 가장 유사도 높은 사용자가 구입한 영화 중 아직 시청하지 않은 영화를 추천합니다.즉, 가중평점이 높은 영화 순으로 목록이 만들어집니다.
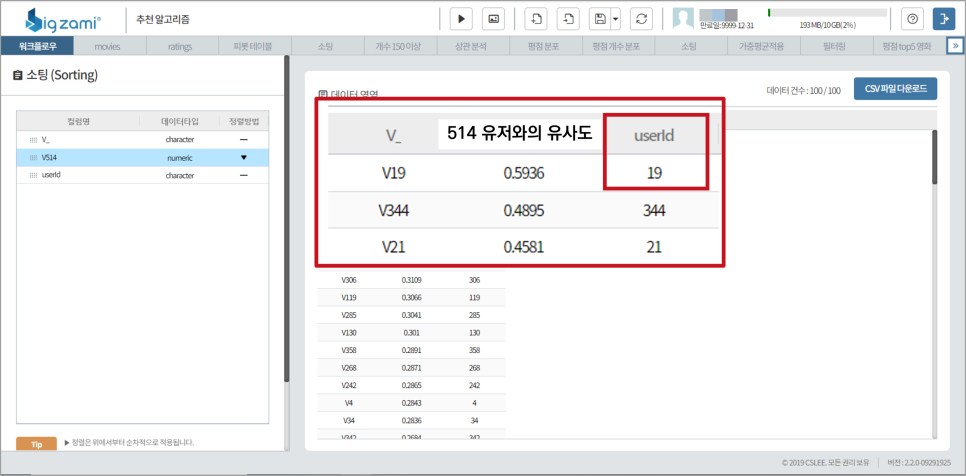
소팅 기능으로 user I D’514’를 선택한 후 유사도 순으로 정렬을 하면 가장 비슷한 사용자가 userid’19라는 것을 알 수 있습니다.

다시 영화의 가중평점과 사용자 ’19’의 평점이 높은 순으로 소팅하면 사용자 ‘514’가 보지 않은 영화의 추천 리스트가 나타납니다.
쇼생크탈출, 대부, 유주얼 서스펙트, 쉰들러리스트 등
취향이 비슷한 사용자가 본 영화 중에서 아직 구입하지 않은 영화가 추천되네요!
장르별 콘텐츠 유사도 기반 필터링
제가 본 콘텐츠의 장르를 분석해서 비슷한 장르와 내용의 영화를 추천하는 방식입니다.
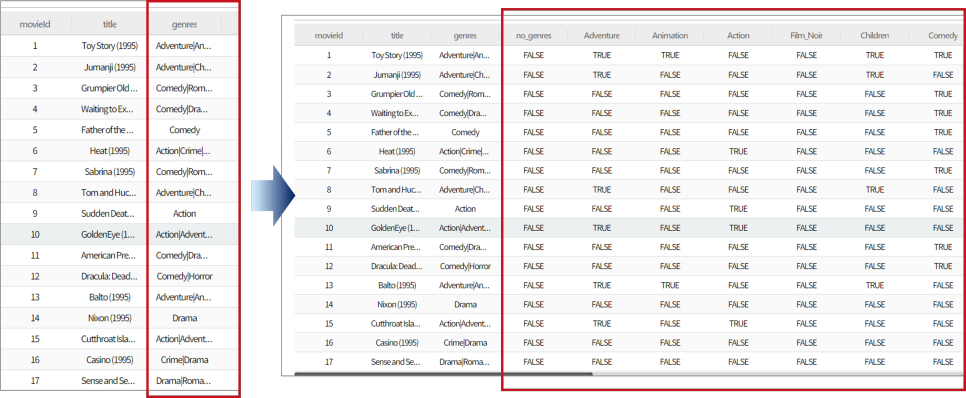
영화 데이터 파일을 로드하고 파생 변수 블록으로 장르 칼럼에 통합되었던 정보를 각각 하나의 컬럼으로 만들어 줍니다.
장르에 따라 필터링 하기 위해서는 먼저 장르 데이터를 전처리해야 합니다.
어드벤처 장르를 포함하며, 어드벤처 컬럼이면 TRUE, 아니면 FALSE입니다.

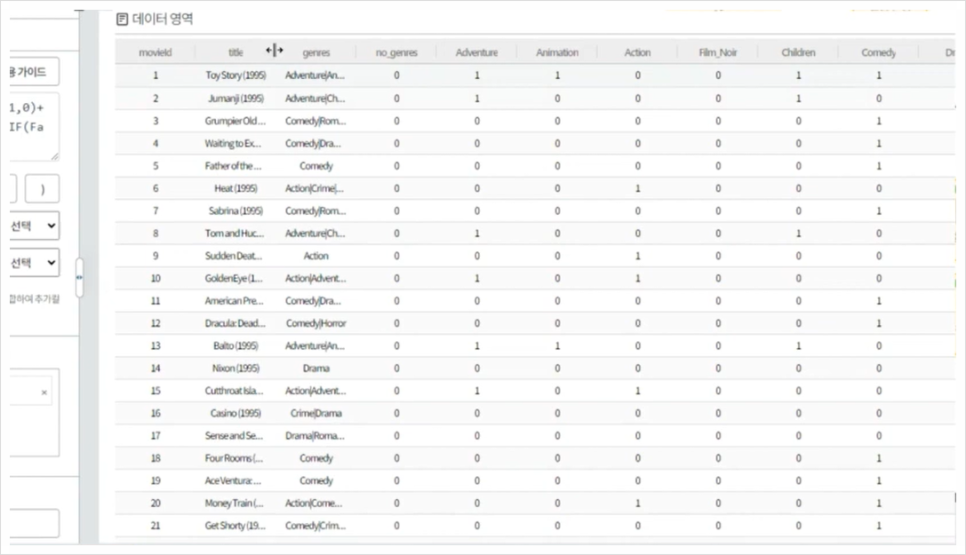
「TRUE=1」, 「FALSE=0」과 같이 미리 숫자 형식으로 바꾸어 연산을 용이하게 하고, 그 후 「토이스토리」와 장르가 비슷한 순서로 리스트 업 했습니다.
그럼 유사도를 계산하여 토이스토리와 장르가 몇 번 겹치는지 확인해 보도록 하겠습니다.